Google’s Brainy Software Can Identify And Describe Objects In Photos
This article is more than 2 years old
 Google is one of the companies whose artificial intelligence and computing algorithms involve something called “deep learning.” Whereas we usually think of software, AI, and computer algorithms as being programmed, deep learning goes a step further, integrating brain-like systems into software so it can learn as it feeds on data. Google has established itself as a leader in this burgeoning field, and its new experimental software shows why.
Google is one of the companies whose artificial intelligence and computing algorithms involve something called “deep learning.” Whereas we usually think of software, AI, and computer algorithms as being programmed, deep learning goes a step further, integrating brain-like systems into software so it can learn as it feeds on data. Google has established itself as a leader in this burgeoning field, and its new experimental software shows why.
GFR has already reported on Google’s ability (and Facebook’s) to identify objects in photos. But until now, the deep learning software has only been able to identify discrete objects — perhaps a television in a photo, or a soccer ball. But now, Google’s software can identify multiple objects in context. In the image above, the program didn’t simply recognize pizza or the stove. It recognized “two pizzas sitting on top of a stove top oven.” This means the software can count and situate — it can also articulate what it sees in complete sentences.

Another impressive feature of this software is its ability to use adjectives. In the four pictures above, you can see the software at work. The two photos on the left are correctly described, while the two on the right demonstrate that the software still makes mistakes. It’s understandable why it would assume the bright yellow car is a school bus (it’s less understandable why a sign plastered with stickers looks like drinks in a fridge). Still, it can identify color, and in the photos on the left, its adjectives are accurate — the field the elephants are on is dry and grassy. The people are indeed playing Frisbee (impressive, given that the software could easily mistake them for playing tag or something else), and they do seem to be young. I do wonder, though, whether the software assuming that only young people play Frisbee, or can it actually analyze the faces of the people and determine their ages?
Google’s software is meant to emulate neural networks in the brain, and this experiment joined two such networks — one that converts images into mathematical representations, and the other that articulates what it sees in grammatically correct full sentences in English. When those two networks are joined, they work in tandem to produce the results above. This is the first such experiment that joins image processing with language.
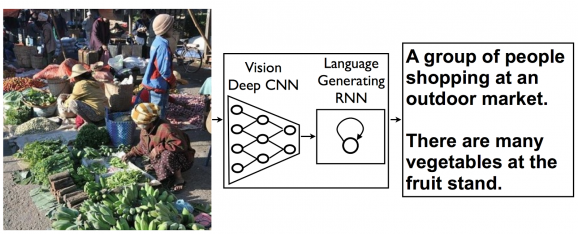
Researchers tested out the software on a bunch of Flickr photos and had a computer-vision software program judge its accuracy, which scored about a 60 on a 100-point scale. Humans who take the test usually score in the 70s, while a similar program developed by researchers at Stanford scored in the 40-50 range. This technology could be used to generate the most specific and annoying ads ever, as well as for enhanced image searching. It’s also possible that this kind of software could help visually impaired people see objects online and/or in the real world. All of this could also be incorporated into virtual reality systems.










